UTF-8 Literals
A UTF-8 literal is a string of characters of class UTF-8. You can specify such literals using basic notation or hexadecimal
notation.
General Formats for Format 1
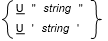
General Formats for Format 2
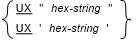
General Rules for all Formats
- Literals of class UTF-8 are only supported in native COBOL.
General Rules for Format 1
- Format 1 is considered basic notation.
- If string contains any DBCS characters, they must be delimited by shift-out and shift-in control characters.
- Due to the variable-width nature of Unicode, the maximum number of characters possible within string varies.
- The following Unicode escape sequences are permitted in
string:
- \uhhhh
- where each h represents a hexadecimal digit in the range 0-9, a-f, and A-F inclusive. This escape sequence corresponds to a Unicode code point from the Basic Multilingual Plane (BMP), within the range U+0000 to U+FFFF.
- \U00hhhhhh
- where each h represents a hexadecimal digit in the range 0-9, a-f, and A-F inclusive. This escape sequence can corresponds to a Unicode code point from the Basic Multilingual Plane, or any Supplementary Planes. This means that as well as the range specified above, it also includes U+10000 to U+10FFFF.
Note: Code points U+D800 to U+DFFF are reserved for the high and low halves of surrogate pairs used by UTF-16; therefore, do not specify \uD800 through \uDFFF and \U0000D800 through \U0000DFFF as Unicode escape sequences in UTF-8 literals.To include \uhhhh or \U00hhhhhh as a string in a UTF-8 literal, the escape character (\) itself can be escaped (using \) to interpret the string literally; for example \\u00FF is not processed as a Unicode escape sequence.
General Rules for Format 2
- Format 2 is the hexadecimal notation.
- hex-string consists of hexadecimal digits in the range 0-9, a-f, and A-F inclusive. Each group of two digits represents a single encoding of a UTF-8 character.
- The sequence of bytes represented by hex-string is validated to ensure that it contains a valid sequence of UTF-8 bytes. If it does, this hexadecimal notation is stored as UTF-8 characters, and results in the content having the same meaning as a basic UTF-8 literal specifying the same characters.
- A UTF-8 literal in hexadecimal notation has a data class and category of UTF-8, and can be used interchangeably with a basic UTF-8 literal.